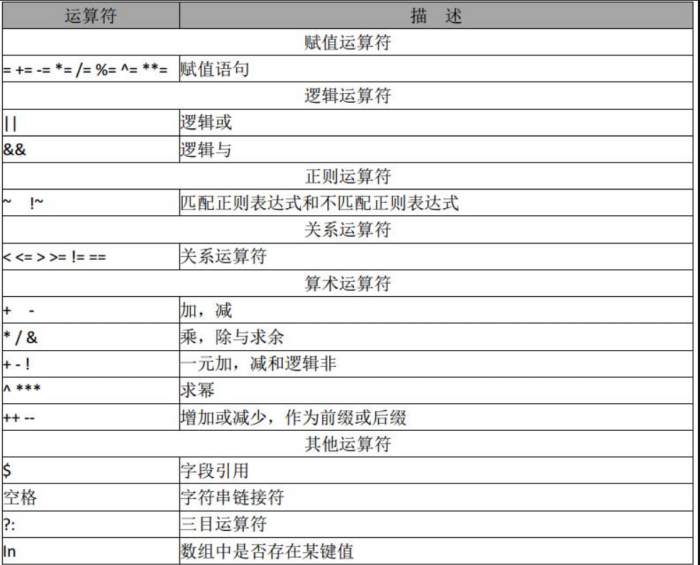
统计 符合某一前缀和为 ***开头的文件和总和
NF 列
NR 行
-F : 以冒号作为一个分隔符号
-v 设置变量
ll | awk '{print $9,$5}' | awk '/^(test)/ {print $2}' | tr -s '\n' ' ' | awk '{for(i=1;i<=NF;i++) a+=$i} {print a}'
• $ awk '/^(no|so)/' test-----打印所有以模式no或so开头的行。
• $ awk '/^[ns]/{print $1}' test-----如果记录以n或s开头,就打印这个记录。
• $ awk '$1 ~/[0-9][0-9]$/(print $1}' test-----如果第一个域以两个数字结束就打印这个记录。 $1 ~ 以[][] 两位数结尾
• $ awk '$1 == 100 || $2 < 50' test-----如果第一个或等于100或者第二个域小于50,则打印该行。
• $ awk '$1 != 10' test-----如果第一个域不等于10就打印该行。
• $ awk '/test/{print $1 + 10}' test-----如果记录包含正则表达式test,则第一个域加10并打印出来。
• $ awk '{print ($1 > 5 ? "ok "$1: "error"$1)}' test-----如果第一个域大于5则打印问号后面的表达式值,否则打印冒号后面的表达式值。
• $ awk '/^root/,/^mysql/' test----打印以正则表达式root开头的记录到以正则表达式mysql开头的记录范围内的所有记录。如果找到一个新的正则表达式root开头的记录,则继续打印直到下一个以正则表达式mysql开头的记录为止,或到文件末尾。
• awk有三种循环:while循环;for循环;special for循环。
• $ awk '{ i = 1; while ( i <= NF ) { print NF,$i; i++}}' test。变量的初始值为1,若i小于可等于NF(记录中域的个数),则执行打印语句,且i增加1。直到i的值大于NF.
• $ awk '{for (i = 1; i<NF; i++) print NF,$i}' test。作用同上。
• breadkcontinue语句。break用于在满足条件的情况下跳出循环;continue用于在满足条件的情况下忽略后面的语句,直接返回循环的顶端。如:
{for ( x=3; x<=NF; x++)
if ($x<0){print "Bottomed out!"; break}}
{for ( x=3; x<=NF; x++)
if ($x==0){print "Get next item"; continue}}
• next语句从输入文件中读取一行,然后从头开始执行awk脚本。如:
{if ($1 ~/test/){next}
else {print}
}
awk 'NR>=2&&NR<=4' user 输出2~4行
awk -F: 'NR>=2&&NR<=4{print $1}' user 找2~4行并输出第1列
awk -F: 'NR==4 ||NR==5{print $1}' user 找4行或5行并输出第1列
awk -F: 'NR>=10 || NR<=20{print $1}' user 找10行以及大于10行的内容, 或者20以内的行, 相当于所有行,再显示第1列
awk -F: 'NR<10 && NR>20{print $1}' user 不存在的行,逻辑错误
常用的例子 用于文件的切割处理
 |
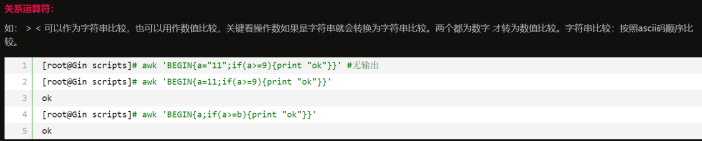
一般可以用于比如说 if 判断比较的一些条件,比如说文本内容的一些处理等
 |
 |
 |
举例 切割 IP 响应报文为 200 的情况下,出现ip次数最多的,按照从大到小排序 前十的情况
cat access.log | awk ' { if($9 == 200) { ip[$1]++}} END { for(i in ip) {print ip[i],i}}' | sort -rn -k 1 | head -n 10