MySQL单表查询 SELECT : DQL
========================================================
使用脚本 方式插入语句。##########################
首先准备好 以下的 三张表
myclass
|
----teacher
----students
----class #有外键约束
 |
简单查询
通过条件查询
查询排序
限制查询记录数
使用集合函数查询
分组查询
使用正则表达式查询 (支持正则表达式, 为了效率和查询优化,不建议 查询语句 使用RE,不建议 在查询表达式中进行 算数运算 加减乘除。。)
简单查询:============================================
SELECT [列1,自定义列,列2] [聚合函数] [distinct] FROM database.table [WHERE] [Order by] [limit] [Group by]
|
从一张表中
从多张表中
其他SQL语句的结果中查询
select * from database.table ;
## 遍历整张表 ,严重消耗资源,很多站点通常会 禁止 类似的查询行为。
#### CONCAT() 函数: 在查询结果中,自定义输出的字符串
MariaDB [myclass]> select concat( '所有人的平均年龄' , avg(年龄) ) from myclass.students;
#### distinct : 查询结果中,去除重复值。
#### from 子句:要查询的关系,可以是某个表, 多个表中 , 其他 Select 语句。
#### where子句: 数值对比: = > < >= <=
字符串比对: 字段=' 字符串 ' 字段 like '字符串%'
多个条件执行逻辑连接 AND OR BETWEEN and IN is null is not null
where [no取反] age>20 and sex='M'
where age>=20 and age <= 25
where age between 20 and 25
where name like '%' 模糊匹配 % 任意字符,_ 任意单个字符。
where name like 'Y%' 以Y开头的
wherer REGEXP '正则表达式' #索引可能没法有效使用
where age in (18,20,25) 散值列表
not in ( )
where aid2 is null
is not null 专用于 空值比对
#### order by 子句:
Oder by 字段1,字段2 {ASC|DESC} ##按照某个字段进行排序, 先按照第一个字段排序,再按照第二个字段排序
#### limit 子句:
select Name AS student_name from database.table limit 2; limit 2,3 [偏移量,显示数] 第二行开始,往下再显示 3 行
#### AS 字段别名:
select Name AS student_name 针对 表,字段来 进行设置 表也可以有别名一般比较少用。
#### 聚合函数: select AVG(price) from students;
sum() min() max() avg() count()
#### Group by 子句; 按照某个 字段,对查询的结果,进行分组。
################# 单表查询 #####################################
 |
### 1.查询一张表: select * from 表名;
### 2.查询指定字段:select 字段1,字段2,字段3….from 表名;
### 3.where条件查询: select 字段1,字段2,字段3 from 表名 where 条件表达式;
例:select * from t_studect where id=1; select * from t_student where age>22; ## 字段不要加引号。 例子: 姓名='曹操'
### 4.带in关键字查询:select 字段1,字段2 from 表名 where 字段 [not]in (元素1,元素2);
例:select * from t_student where age in (21,23); 查询班级中,年龄为 21岁,和 23 岁的 同学的名字。
### 5.带 between and 的范围查询:select 字段1,字段2 from 表名 where 字段 [not]between 取值1 and 取值2;
例:select * from t_student where age between 21 and 29; select * from t_student where age not between 21 and 29;
### 6.带like的模糊查询:select 字段1,字段2… from 表名 where 字段 [not] like '字符串';
“%'代表任意字符;
“_'代表单个字符;例:select * from t_student where stuName like '张三';
select * from t_student where stuName like '张三%';
select * from t_student where stuName like '%张三%'; //含有张三的任意字符
select * from t_student where stuName like '张三_'
### 7.空值查询:select 字段1,字段2…from 表名 where 字段 is[not] null;
SELECT 姓名 FROM db_class.students WHERE `期数`="";
### 8.带and的多条件查询:select 字段1,字段2…from 表名 where 条件表达式1 and 条件表达式2 [and 条件表达式n]
例:SELECT 姓名,`就业薪资` FROM db_class.students WHERE `所选课程`=2 AND `就业薪资`>12000;
### 9.带or的多条件查询select 字段1,字段2…from 表名 where 条件表达式1 or 条件表达式2 [or 条件表达式n]
例:SELECT 姓名,`所选课程` FROM db_class.students WHERE `所选课程`=2 OR `所选课程`=1 //或者,条件只要满足一个
### 10.distinct去重复查询:select distinct 字段名 from 表名;
mysql> select distinct stu_age from class.students order by stu_age; ##查询班级学生,的年龄分布情况。
### 11.对查询结果排序order by:select 字段1,字段2…from 表名 order by 属性名 [asc|desc]
例:SELECT 姓名,`就业薪资` FROM db_class.students WHERE `所选课程`=2 AND `就业薪资`>12000 ORDER BY `就业薪资` DESC;
//降序,从大到小 //升序,asc 是默认,可以不写
### 12.limit 分页查询:select 字段1,字段2,…from 表名 limit 初始位置,记录数;
mysql> select stu_name,stu_mon from class.students order by stu_mon desc limit 3; ##就业工资排名前三位的同学。
### 13.分组查询 group bygroup by 属性名 [having 条件表达式][with rollup]
1.单独使用(无意义,不推荐单独使用);
2.与 group_concat()函数一起使用;
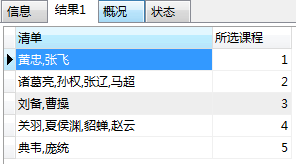
例:SELECT GROUP_CONCAT(stu_name) AS 清单 , stu_class FROM class.students GROUP BY stu_class;
统计出选择了 各门 课程的 同学的名单。
 |
3.与聚合函数一起使用;例:
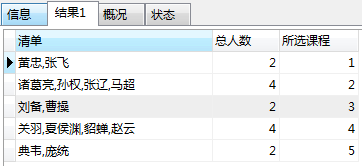
统计每一门课程选择同学的清单,并统计人数。
SELECT GROUP_CONCAT(姓名) AS 清单 , COUNT(姓名) AS 总人数 , 所选课程 FROM students GROUP BY 所选课程;
 |
4.与 having 一起使用(显示输出的结果);
having字句可以让我们筛选成组后的各种数据,where字句在聚合前先筛选记录,也就是说作用在group by 和 having字句前。
而 having子句在 聚合后 对组记录进行筛选。
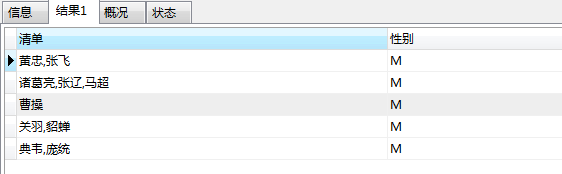
例1: 统计每一门课程选择同学的清单,并统计人数,但是我们只看 男生。
SELECT GROUP_CONCAT(姓名) AS 清单 ,`性别` FROM myclass.students WHERE 性别='M' GROUP BY 所选课程;
 |
值得注意的是,使用 having 时,having 的条件字段引用必须 先被 select 装载进来,后续才可以使用,
优先级小于 where子句, where 子句 在 分组前执行。
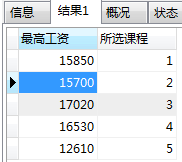
例子2: 每个方向课程中,就业薪资 最高的。
SELECT MAX(就业薪资) AS 最高工资 FROM myclass.students; ##整个表中,该字段的最大值。
SELECT MAX(就业薪资) AS 最高工资,所选课程 FROM myclass.students GROUP BY 所选课程;
 |
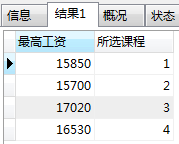
例子3: 每个方向课程中,就业薪资最高能超过 15000 的。
SELECT MAX(就业薪资) AS 最高工资,所选课程 FROM myclass.students GROUP BY 所选课程 HAVING 最高工资>15000;
 |
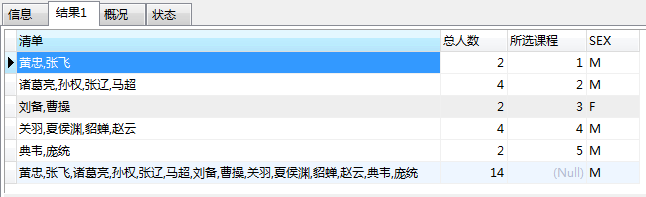
5.与 with rollup 一起使用(最后加入一个总和行);
例子: SELECT GROUP_CONCAT(姓名) AS 清单,COUNT(姓名)AS 总人数,所选课程,性别 AS SEX FROM students GROUP BY 所选课程 WITH ROLLUP;
 |
password() now() current_timestamp() length() concat() group_concat() conut() sum() avg() min() max() version()